April 10, 2026 • Sivam Pillai • 3 minutes read
Eval Sakhi: Making AI Evaluation Less of a Blank Page
A small agent I built to help structure evals before your AI project hits production
A few days ago, I posted about AI Evals.
What I didn’t expect was what happened next.
The comments, DMs, and side conversations were far more interesting than the post itself.
There was a clear pattern:
“I know evals are important… I just don’t know where to start.”
And honestly, that stuck with me.
The Real Problem: Evals Sound Simple Until You Try
If you’ve built any AI system—LLM-based or otherwise—you’ve probably faced this moment.
You sit down to “design evals” and suddenly it’s a blank page.
- What metrics do I track?
- What failure cases matter?
- What does “good” even mean here?
So what happens instead?
We default to some version of a vibe check:
- “This looks right”
- “This response sounds reasonable”
- “This anomaly seems correct”
That works in demos.
But in production?
“Looks right” is not a metric.
The Eval Gap I Keep Seeing
Across very different systems—from LLM agents to industrial AI—the same pattern shows up.
1. Accuracy Can Be Misleading
A model can be 99% accurate and still fail where it matters.
- Rare failures don’t show up in averages
- One bad LLM response can break trust instantly
2. Confidence ≠ Correctness
LLMs sound confident even when wrong.
Sensor systems can confidently signal faults that don’t exist.
We mistake fluency or signal clarity for correctness.
3. The Expert Bottleneck
“Let’s have a human review it” doesn’t scale.
- You can’t review every LLM output
- You can’t manually validate high-frequency sensor data
Manual evals don’t just slow things down—they introduce inconsistency.
That’s What Led Me to Build Eval Sakhi
Over the weekend, I wanted to try something simple.
Not a full platform. Not a heavy system.
Just something that helps you get past that blank page.
So I built Eval Sakhi—an AI agent that takes your use case and generates a structured evaluation plan.
It helps you think through:
- what success should look like
- what metrics actually matter
- where your system might fail
- what you should test before shipping
Nothing fancy.
Just a better starting point.
See It in Action
Here’s a quick demo of how it works:
How It Works (Under the Hood)
The flow is intentionally simple.
- You describe your AI project
- The system validates if it’s a real AI use case
- It extracts relevant context (including RAG when useful)
- It generates a structured evaluation plan in markdown
- You can export it as a PDF for sharing
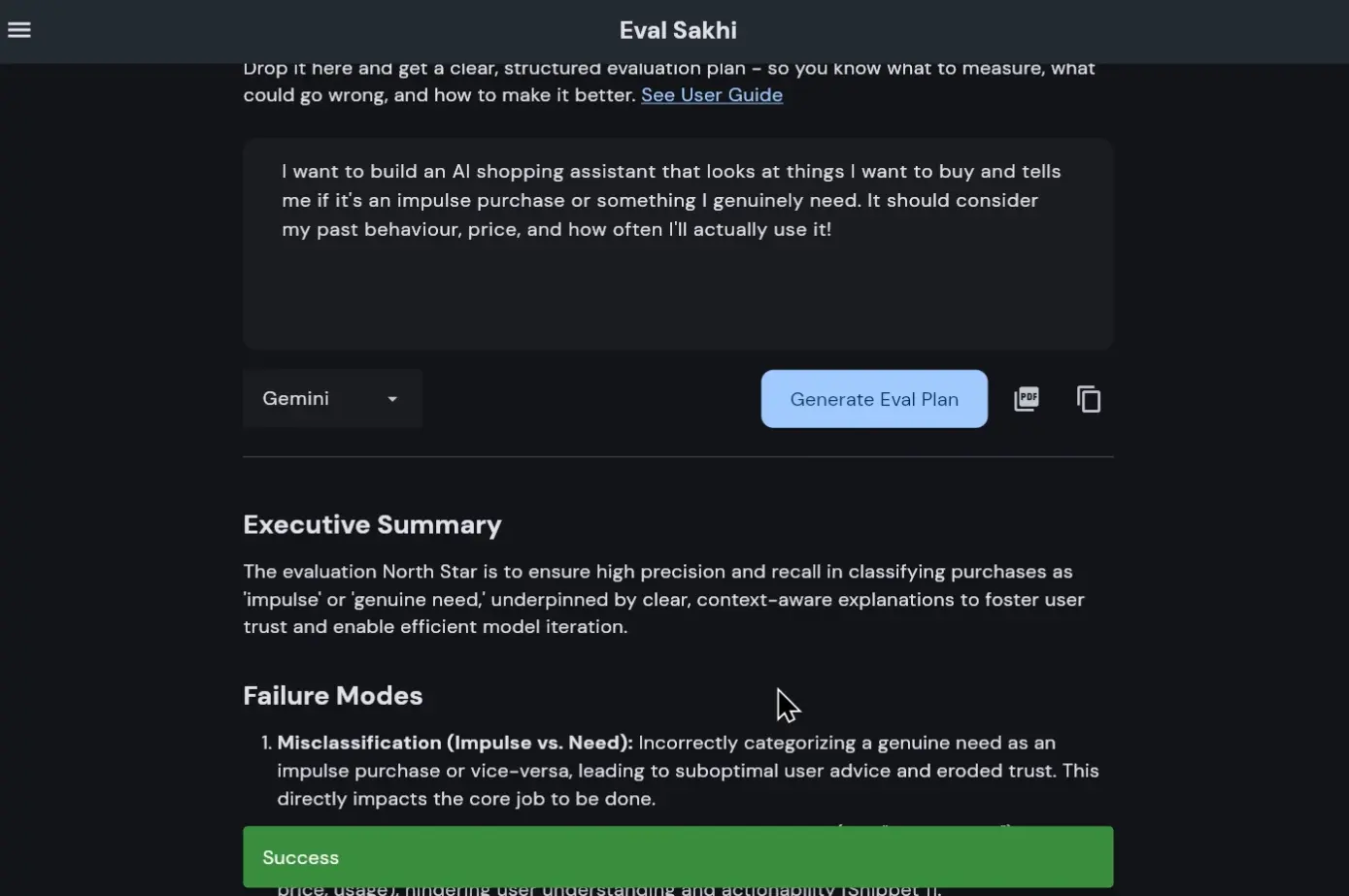
What the Output Actually Looks Like
Instead of vague advice, you get something concrete:
Metrics That Matter
Not just accuracy or BLEU.
But things like:
- task success rate
- user trust signals
- failure severity
- latency vs quality tradeoffs
Failure Modes
This is where it gets interesting.
It explicitly calls out:
- hallucination risks
- edge cases
- ambiguous inputs
- system boundary failures
Why This Matters (At Least to Me)
There’s a phrase I’ve been hearing a lot:
“Pilot purgatory — where good AI goes to wait for proof it can’t provide.”
And most of the time, it’s not the model that’s the problem.
It’s that we never defined:
- what success looks like
- how to measure it
- what failure means
Eval Sakhi doesn’t solve evaluation.
But it makes starting easier.
And I’m starting to believe that’s the real bottleneck.
A Few Practical Notes
- You’ll need to add your own OpenAI or Gemini API key
- Keys are stored locally for the session (not on the server)
- Your inputs are not used for training
If you need a trial key, you can reach out at contact@sivampillai.com.
What’s Next
A few things I’m planning:
- Support for more models (DeepSeek, LLaMA, Gemma)
- Optional login so you don’t need to bring your own API key
- Iterating on eval depth and customization
Also—
I’ll be open-sourcing the project on GitHub shortly.
I’ll update this article with the link when it’s live.
Launch 🚀
Eval Sakhi is live on Product Hunt on April 11, 2026.
If this sounds interesting, you can check it out here:

Eval Sakhi
Closing Thought
This started as a small weekend experiment.
Not to “solve evals”—but to make them less intimidating to begin.
Because right now, the hardest part isn’t building AI.
It’s knowing whether it actually works.
And maybe…
we just needed a better way to start asking that question.
Related from the thinking lab
Other things connected by tags — essays, projects, quotes, notes, and collections.