June 1, 2016 • Sivam Pillai • 5 minutes read
Evolution of Deep Learning Techniques and Tools
The Ideas, Breakthroughs, and Challenges That Shaped Modern AI
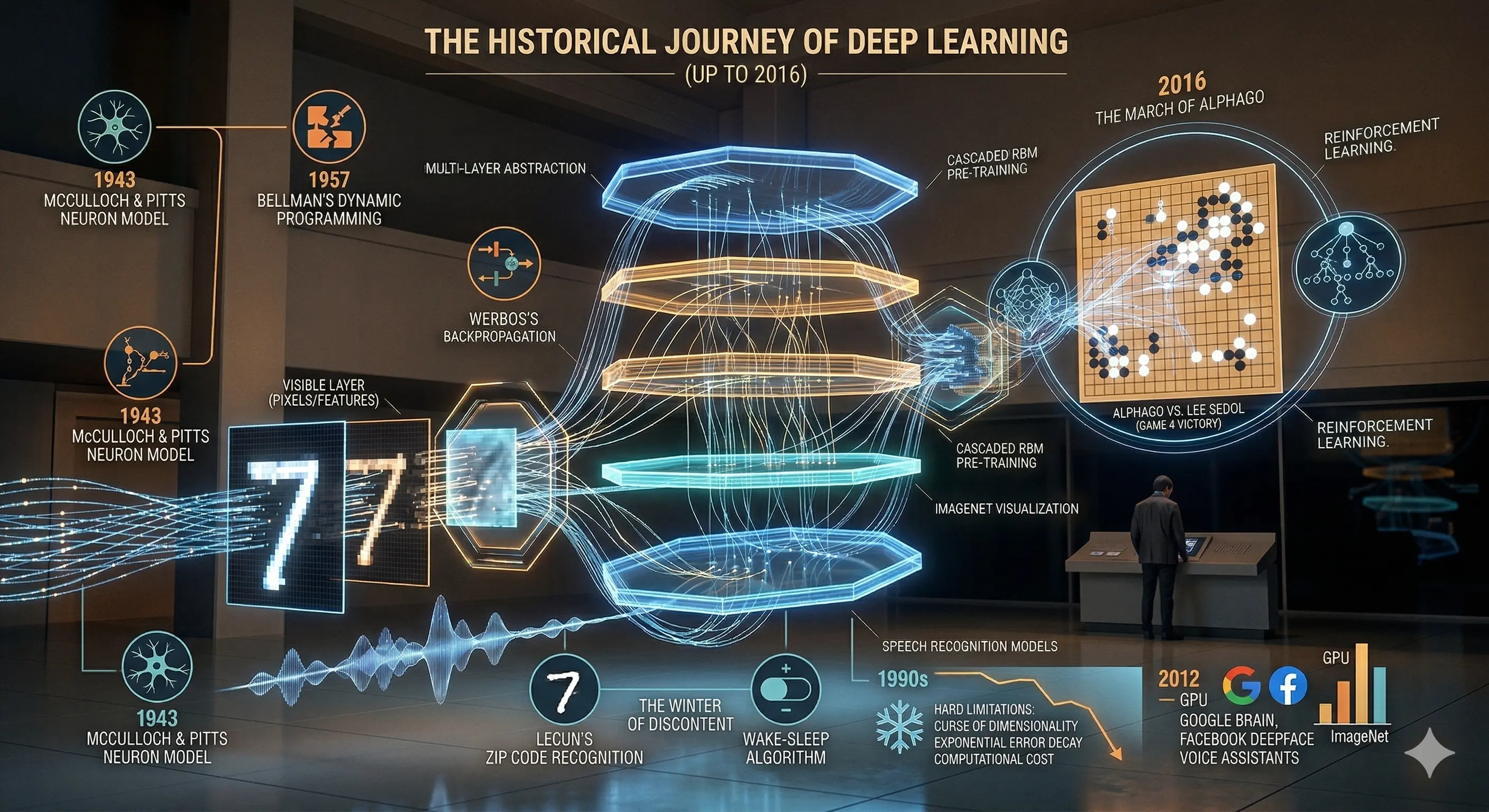
Deep learning, as understood in 2016, marks the convergence of decades of theoretical exploration with the practical availability of computational power. Moving beyond traditional machine learning approaches that rely on handcrafted features, it introduces a paradigm where systems learn hierarchical representations directly from raw data. This shift becomes especially significant when working with high-dimensional inputs such as images, audio, and sensor data—domains where manual feature design is both limiting and inefficient. By enabling models to automatically extract structure and meaning through layered abstractions, deep learning offers a more scalable approach to complex pattern recognition, while still grappling with fundamental challenges such as the curse of dimensionality.
🧬 Foundations: From Neurons to Algorithms (1940–1980)
The conceptual foundation of deep learning is rooted in early attempts to model human cognition mathematically. Researchers explored how simple computational units could simulate biological neurons and how complex problems could be decomposed into manageable parts.
These early ideas did not immediately translate into practical systems but established the theoretical groundwork for learning algorithms.
Key insight: The ability to propagate error backward through a network made learning feasible in multi-layer systems.
- McCulloch & Pitts (1943): Mathematical model of neurons
- Bellman (1957): Dynamic programming for problem decomposition
- Werbos (1975): Backpropagation for training neural networks
⚙️ Early Implementations: Promise Meets Reality (1980–2000)
By the late 20th century, neural networks began demonstrating real-world applicability, particularly in pattern recognition tasks. However, these systems were still limited in depth and scalability.
The focus during this period was on proving that neural networks could work—not yet on making them efficient or widely deployable.
[IMAGE: Diagram of a simple neural network showing input, hidden layers, and output]
Key insight: Early successes validated the approach but exposed significant practical limitations.
- Handwritten digit recognition (LeCun, 1989)
- Wake-sleep algorithm for unsupervised learning (1995)
⚠️ The Quiet Years: Challenges and Decline
Despite promising early results, the field experienced a slowdown in the 1990s due to a combination of theoretical and practical constraints. Training deep networks proved difficult, and available hardware could not support the required computations.
At the same time, alternative machine learning methods offered more reliable performance, drawing attention away from neural networks.
Key insight: Neural networks were powerful in theory but inefficient in practice during this phase :contentReference[oaicite:1]{index=1}
- Vanishing gradients and slow learning rates
- High computational cost with limited hardware support
- Competition from SVMs, HMMs, and other methods
🔥 The Turning Point: Layer-wise Learning (2007)
A significant breakthrough came with the introduction of layer-wise training methods using Restricted Boltzmann Machines. This approach enabled networks to learn meaningful representations before fine-tuning with labeled data.
By shifting the focus from direct classification to representation learning, this method reduced the dependence on large labeled datasets and improved training efficiency.
Key insight: Learning intermediate representations made deep networks more practical and scalable.
- Use of RBMs for unsupervised pre-training
- Reduction in effective dimensionality
- Improved performance with limited labeled data
⚡ Acceleration Phase: Deep Learning Gains Momentum (2010s)
Entering the 2010s, deep learning began to scale rapidly due to improvements in both hardware and data availability. Graphics Processing Units (GPUs), originally designed for rendering, proved highly effective for neural network computations.
At the same time, benchmark competitions began to showcase the superior performance of deep learning models, attracting industry attention.
Key insight: Progress shifted from incremental improvements to significant performance leaps.
- GPUs enabled faster matrix computations
- Success in benchmarks like ImageNet and CIFAR-10
- Increased investment from major technology companies
🌍 Real-World Applications (as of 2016)
By 2016, deep learning had moved beyond research and into real-world deployment across multiple domains. Its strength lies in identifying complex patterns across different types of data, making it applicable across industries.
These applications demonstrate the versatility of deep learning rather than dominance in any single domain.
Key insight: Deep learning is a general-purpose pattern recognition tool adaptable across modalities.
- Computer vision: face recognition, image search
- Speech processing: voice recognition and synthesis
- Text analytics: sentiment analysis, fraud detection
- Video analytics: motion and threat detection
- Healthcare: emerging use in imaging and diagnostics
🏗️ Tools and Ecosystem (2016 Snapshot)
The tooling ecosystem around deep learning began maturing rapidly during this period. Open-source frameworks made experimentation more accessible, while cloud platforms enabled scalable deployment.
This marked a transition from purely academic exploration to practical engineering systems.
Key insight: Accessibility of tools played a crucial role in accelerating adoption.
- Rise of open-source deep learning frameworks
- Integration with cloud-based infrastructure
- Increasing participation from developers and researchers
🔭 Future Directions (From a 2016 Lens)
As of 2016, deep learning is still an evolving field with significant potential and unresolved challenges. The trajectory suggests continued growth driven by better algorithms, more data, and increased computational resources.
The next phase is expected to focus on making these systems more efficient, generalizable, and applicable across domains.
Key insight: The challenge is no longer feasibility—but scalability, generalization, and efficiency.
- Improving optimization and training algorithms
- Developing general-purpose learning systems
- Expanding into new interdisciplinary applications
🧩 Closing Reflection
The journey of deep learning spans decades—from theoretical neuron models to practical systems influencing real-world applications. What distinguishes the current phase is not a single breakthrough, but the alignment of multiple factors: data availability, computational power, and algorithmic refinement.
As of 2016, deep learning stands at an inflection point—promising, impactful, yet still incomplete.
Final thought: Deep learning is not a finished solution, but a rapidly maturing framework that is reshaping how machines interpret and interact with data.
Related from the thinking lab
Other things connected by tags — essays, projects, quotes, notes, and collections.